Yeah, and eating hot dogs also goes against human nature. That shit didn’t exist in 3,500 BCE.
- 3 Posts
- 162 Comments
Joined 1 year ago
Cake day: October 19th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 14·8 days ago
14·8 days agoPOV you hid your copy of The Guy Game in your neighbour’s house
 81·9 days ago
81·9 days agoThe easiest, but not necessarily the most applicable answer, is that it is possible to wager money on the outcome of sports games. Very large sums of money. Ruinous, life-altering sums.
The more common answer is that this is a sense of personality for some people. They identify with a certain sports team and spend a lot of their time cheering them on and building up the belief that they are the best team, undefeatable under any fair circumstance. When that team loses, they then take it personally. After all, if their team lost, could it mean they’re not actually the best team? Did I choose wrong?
No. Impossible. It’s those damn referees, blind as they are, missing the most obvious fouls and treating my team unfairly, punishing my team’s players more harshly for the tiniest infractions. Nay, not even that; my team didn’t break the rules; it’s that other team’s fault!
&c., &c., until you get bored.
It isn’t reasoning driving these decisions. It’s emotion. And before any of us get too haughty about it, it’s also a very human reaction. Humans were not designed to reason, we were designed to feel. And yes, everyone has a set of circumstances that will cause their logical processing to shut off and allow emotion to take control. It just might not be sports.
No, what I said is true if you use zero-based numbering. But when communicating with others in English, the label “first” refers to the element with the smallest index. In zero-based numbering, the label “zeroth” refers to the element with the lowest index. It’s just not the default in English, but you can definitely use zero-based numbering in English if you’re willing to edit the configuration files.

That’s because you use English, a language where ordinals traditionally begin at one.
My argument is purely pedantic. Pedantry is the lifeblood of programmer “humour”.
I’m not arguing that we should adopt zero-based numberingin real-life human applications. I am arguing that in zero-based numbering, the label “zeroth” refers to the same ordinal as “first” in one-based numbering. I am poking fun at the conversion between human one-based numbering and computers’ zero-based numbering. That is why I am saying it should be called
zeroth(); because human language should adapt to match the zero-based numbering their tools use. Whether I actually mean what I say—well, I leave that up to you.It does not matter why indexes start from zero in computing. The memory offset argument is only salient if you are using it as an argument for why computers should use zero-based numbering. It is not an argument against the properties of zero-based numbering itself.
Zero-based indexing redefines the meaning of the labels “first”, “second”, “third”, and so on. It adds a new label, “zeroth”, which has the same ordinal value as “first” in one-based indexing. The word “first” does not mean “the element with the lowest index” in zero-based indexing.
If you are using a zero-based numbering system, you would absolutely say that
array[2]is the final element in the array, that element having the ordinal label “second”, and yet the length of the array is 3 (cardinal). There is no fundamental connection between the ordinal labels “zeroth”, “first”, “second”, and “third” and the cardinal numbers 0, 1, 2, and 3. The similarities are purely an artefact of human language, which is arbitrary anyway. You can make an equally mathematically valid ordinal numbering system that assigns “third” to the element with the smallest index, “fourth” to the next-smallest, and so on. That ordinal numbering system is mathematically coherent and valid, but you’re just causing trouble for yourself when it comes time to convert those ordinals (such as array indexes) into cardinals (such as memory locations or lengths of fencing to buy).You can make an argument for why one-based numbering is more convenient and easier to use, but you cannot use the notion that zero-based numbering doesn’t make sense given the assumed context of one-based numbering as an argument for why zero-based numbering is invalid.
I encourage you read up what is meant by “zero based numbering” because you and everyone else who has replied to me has tried to use “but that’s not how it works in one-based numbering” as an explanation for why I’m wrong. This is as nonsensical of an argument as trying to say i (the imaginary unit) is not a number because it’s not on the number line. It’s only not a number in the domain of the real numbers. Similarly, zero-based numbering is only nonsensical in the context of one-based indexing.
It does not matter why indexes start from zero. The memory offset argument is only salient if you are using it as an argument for why computers should use zero-based numbering.
Okay, I will admit, you got me there. I did confuse indexing with numbering. From now on I will use the term “numbering” instead.
It is entirely how ordinal numbers work in zero-based numbering. There is no “right way” for ordinal numbers to work. You can create a valid ordinal numbering system starting from any integer, or just some other ordered list. You cannot assume one-based numbering is “correct” and use it as an argument against numbering beginning from any other number.
I encourage you read up what is meant by “zero based numbering” because you and everyone else who has replied to me has tried to use “but that’s not how it works in one-based numbering” as an explanation for why I’m wrong. This is as nonsensical of an argument as trying to say i (the imaginary unit) is not a number because it’s not on the number line. It’s only not a number in the domain of the real numbers. Similarly, zero-based numbering is only nonsensical in the context of one-based indexing.
Zero-based numbering would number “foo” as the zeroth element, “bar” as the first element, and “baz” as the second element. “zeroth”, “first”, and “second” are labels representing ordinals. Your list has a length of 3 (which is a cardinal quantity unrelated to ordinals).
Although, I would like to point out, it is perfectly valid to construct an ordinal labelling system that assigns “fifth” to the element with the lowest index, “sixth” to the next, and so on. That system is mathematically coherent but it is just troublesome to when it comes time to convert ordinal numbers (such as the index of the last fence-post) to cardinal numbers (such as the length of fence to buy).
But this is now getting into the weeds of pure mathematics and most people here are engineers.
That’s because the word “first” in
first()uses one-based indexing. In true programmer fashion it would have been calledzeroth()but that is wholly unintuitive to most humans.I maintain that the element with the lowest index is called the “zeroth” element in zero-based indexing and “first” in one-based indexing. The element with index N is the Nth element.
Bullshit.
Every programmer knows that
'A'in['A', 'B', 'C', 'D']would be the 0th item; the first item is'B'
Rulers measure cardinal quantities and not ordinal ones. There is no cardinal numbering scheme that starts at 1, all of them “start” at 0. For ordinal numbering schemes, the symbols are arbitrary anyway and you can start with whatever you want. It’s equally valid to start with 1, 0, -1, A, or “aardvark”. The only benefit to picking 1 as the start is to make it easier to count with your fingers while picking 0 lets you easily convert an ordinal quantity to a cardinal one.
I don’t have a problem with snaps as a technology. If you want to use them, then who am I to judge?
But what I do have a problem with is when I don’t have a choice and I am being forced to use what the distro maintainers think is good for me. That is what finally made me quit Ubuntu and switch to Fedora.

Almost none of the people who are excited about AI know anything about computer science. I say this someone who always encounters idiots claiming my computer science degree will soon be obsolete because of AI… lol

 21·1 month ago
21·1 month agoWhat are the implications of this?
Other people have described the health effects, so I’ll describe the chemistry. Fats are made of long chains of carbon atoms surrounded by hydrogen atoms attached to a “head”, which is made of other elements or structures. Carbon atoms normally can make a total of 4 bonds. Hydrogen atoms can make 1 bond.
Carbon being able to make 4 bonds means that in the chain of carbon and hydrogen atoms in fat molecules, each carbon atom makes a bond with the carbon atom before it in the chain, a bond with the carbon atom after it in the chain, and then bonds with two hydrogen atoms separately off to the side. This makes a total of 4 bonds. If all of the carbon atoms in the chain are like this, that’s “saturated fat”, because the chain of carbon is completely “saturated” with hydrogen atoms.
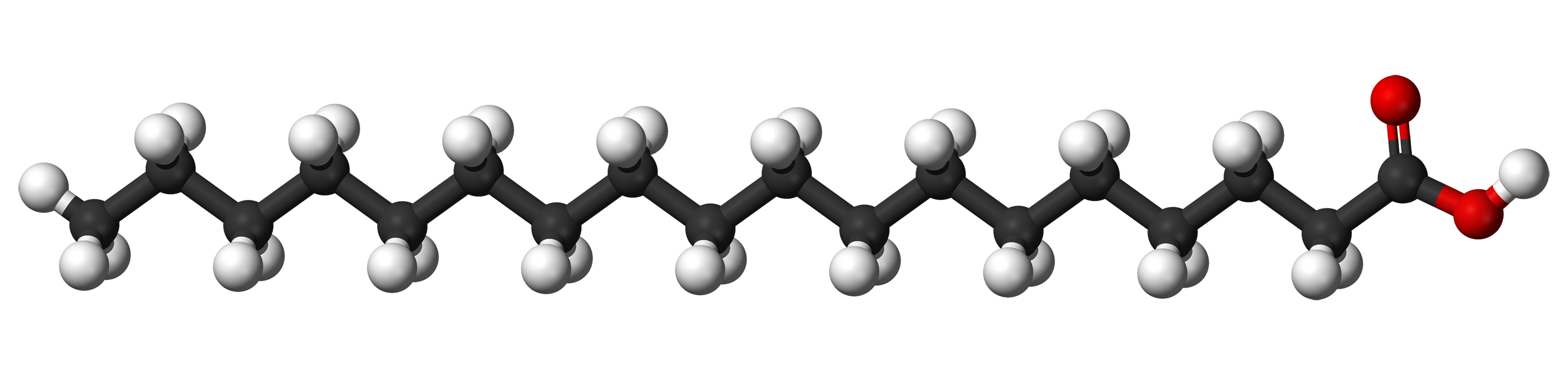
(Hydrogen atoms are white, carbon atoms are black, oxygen atoms are red)
Saturated fats have the often desirable property of being able to be tightly packed together, and thus are typically solid at room temperature. Butterfat is mostly saturated fat.
However, carbon atoms can also make a double bond with other carbon atoms. If a particular carbon atom in the chain makes a double bond with the carbon atom before it, it could cause a bend in the chain of carbon atoms. In that case, it also means that those particular carbon atoms in the chain that have formed a double bond with each other only have 1 available bond left (after also forming a separate single bond with the carbon atom before or after it), so it can only bond with one hydrogen atom. These are, therefore, called “unsaturated fats”, and because they don’t pack together easily, they are typically liquid at room temperature.
If there is a single double bond in the chain, it’s a monounsaturated fat.
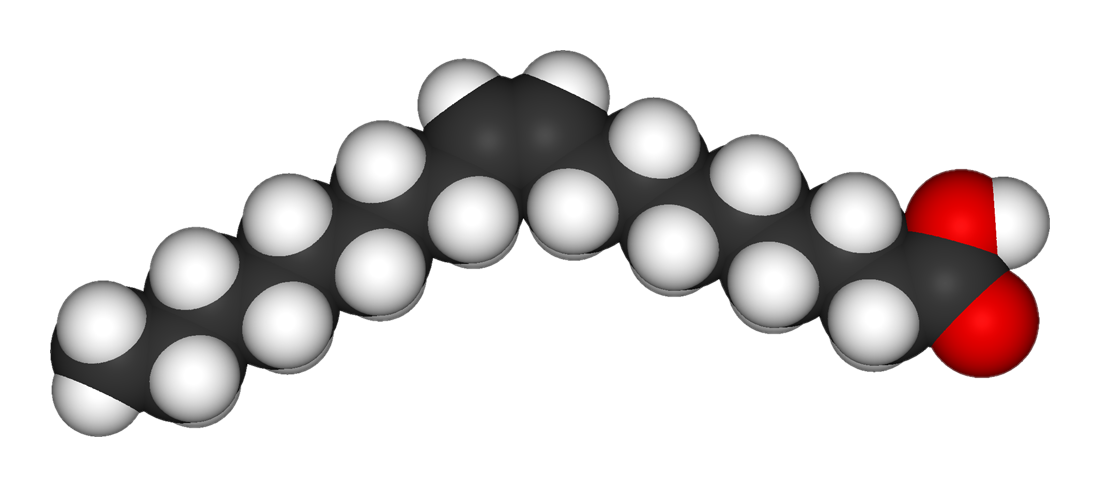
If there are two or more double bonds, it’s a polyunsaturated fat.
Notice how the hydrogen atoms connected to the double-bonded carbon atoms in unsaturated fats can be connected to either the same side or the opposite sides of the two hydrogen atoms. If they’re on the same side, they are called cis-unsaturated fats. If they’re on opposite sides, they are trans-unsaturated fats, or trans fats in short.
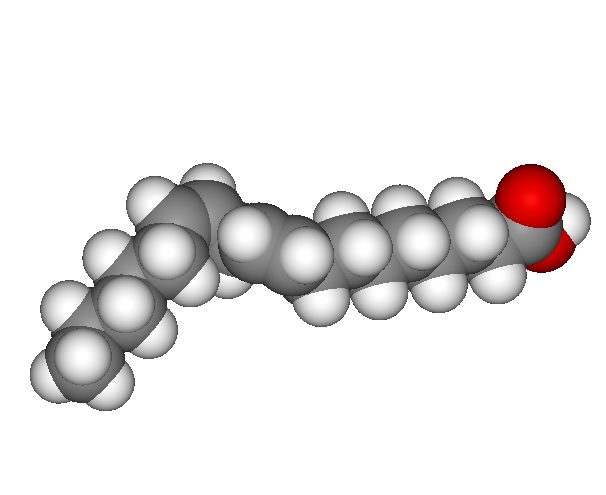
This is oleic acid, a cis monounsaturated fat commonly found in many vegetable oils:
While this is vaccenic acid, a trans-monounsaturated fat. It is found naturally in butter and human milk and is not particularly bad for you:
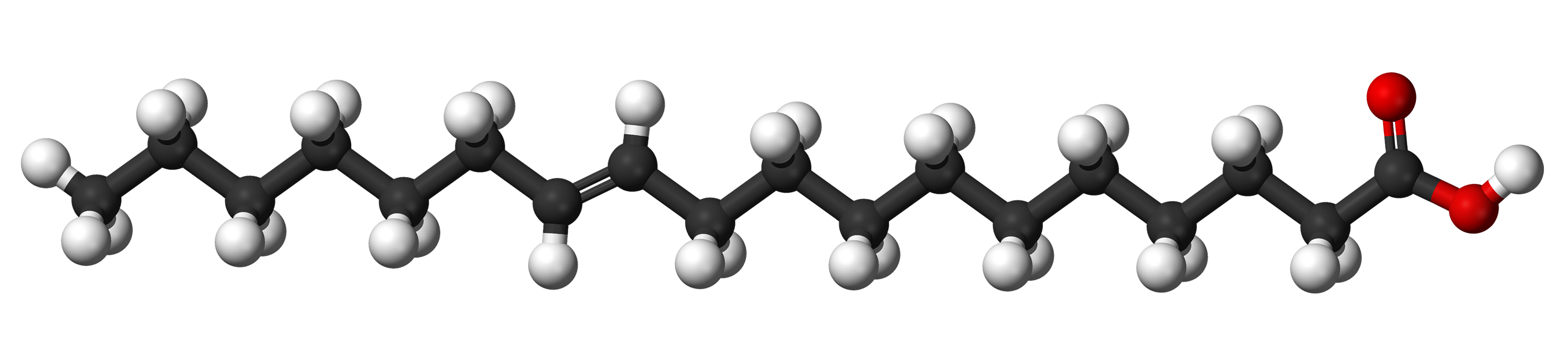
Note that this is NOT the same picture as the one I showed for saturated fat. The 7th and 8th carbon atoms from the left are double-bonded and, therefore, are each missing a hydrogen atom. The one remaining hydrogen atom on each is bonded on opposite sides.
Note that trans-unsaturated fats are also pretty straight. This means that they can also pack together with saturated fats to make a solid product at room temperature.
“Hydrogenation” is the process of adding hydrogen to unsaturated fats to saturate them. This means that liquid oil can be processed into a solid product. That’s how margarine and shortening are made. In previous years, partially hydrogenated oils that weren’t fully hydrogenated could leave substantial quantities of trans-unsaturated fats left in the product, but after health concerns, many countries’ food safety authorities banned these artificial trans fats. Fully hydrogenated fats consist of only saturated fats since they have been “fully” hydrogenated, and that is what food manufacturers have been doing instead.
The exact data is Figure 1, chart A. It seems the mean is around 4,000-5,000 μg/g, which is indeed 0.4-0.5%
I really had to run a fact check on this but it really does seem to be true.
Brains are 0.5% plastic by weight and with an average human brain mass of 1.3 kg, that means humans, on average, have 6.5 g of plastic in their brain
 55·1 month ago
55·1 month agoFor what it’s worth, English Wikipedia editors reached a consensus to deprecate (ban) it for unrealiability last year: https://en.wikipedia.org/wiki/Wikipedia:Reliable_sources/Noticeboard/Archive_424#RFC:_The_Cradle
The following notes are present:
The Cradle is an online magazine focusing on West Asia/Middle East-related topics. It was deprecated in the 2024 RfC due to a history of publishing conspiracy theories and wide referencing of other deprecated sources while doing so. Editors consider The Cradle to have a poor reputation for fact-checking.
This is kind of what people are missing. These people really do produce millions of dollars worth of labour. That’s how entertainers are paid; the more people want to see their performance, the more that performance is worth.



.gov and .mil are controlled by the American government and they are reserved for use by American government websites and American military websites respectively.