bahmanm
Husband, father, kabab lover, history buff, chess fan and software engineer. Believes creating software must resemble art: intuitive creation and joyful discovery.
Views are my own.
- 15 Posts
- 80 Comments

I didn’t like the capitalised names so configured xdg to use all lowercase letters. That’s why
~/optfits in pretty nicely.You’ve got a point re
~/.local/optbut I personally like the idea of having the important bits right in my home dir. Here’s my layout (which I’m quite used to now after all these years):$ ls ~ bin desktop doc downloads mnt music opt pictures public src templates tmp videos workspacewhere
binis just a bunch of symlinks to frequently used apps fromoptsrcis where i keep clones of repos (but I don’t do work insrc)workspaceis a where I do my work on git worktrees (based offsrc)

 151·9 months ago
151·9 months agoThanks! So much for my reading skills/attention span 😂
Which Debian version is it based on?
RE Go: Others have already mentioned the right way, thought I’d personally prefer
~/opt/goover what was suggested.
RE Perl: To instruct Perl to install to another directory, for example to
~/opt/perl5, put the following lines somewhere in your bash init files.export PERL5LIB="$HOME/opt/perl5/lib/perl5${PERL5LIB:+:${PERL5LIB}}" export PERL_LOCAL_LIB_ROOT="$HOME/opt/perl5${PERL_LOCAL_LIB_ROOT:+:${PERL_LOCAL_LIB_ROOT}}" export PERL_MB_OPT="--install_base \"$HOME/opt/perl5\"" export PERL_MM_OPT="INSTALL_BASE=$HOME/opt/perl5" export PATH="$HOME/opt/perl5/bin${PATH:+:${PATH}}"Though you need to re-install the Perl packages you had previously installed.
This is fantastic! 👏
I use Perl one-liners for record and text processing a lot and this will be definitely something I will keep coming back to - I’ve already learned a trick from “Context Matching” (9) 🙂
Update 1
Thanks all for your feedback 🙏 I think everybody made a valid point that the OOTB configuration of 33 requests/min was quite useless and we can do better than that.
I reconfigured timeouts and probes and tuned it down to 4 HTTP GET requests/minute out of the box - see the configuration for details.
🌐 A pre-release version is available at lemmy-meter.info.
For the moment, it only probes the test instances
I’d very much appreciate your further thoughts and feedback.
Agreed. It was a mix of too ambitious standards for up-to-date data and poor configuration on my side.
sane defaults and a timeout period
I agree. This makes more sense.
Your name will be associated with abuse forevermore.
I was going to ignore your reply as a 🧌 given it’s an opt-in service for HTTP monitoring. But then you had a good point on the next line!
Let’s use such important labels where they actually make sense 🙂
beyond acceptable use
Since literally every aspect of lemmy-meter is configurable per instance, I’m not worried about that 😎 The admins can tell me what’s the frequency/number they’re comfortable w/ and I can reconfigure the solution.
You can hit the endpoint /api/v3/site for information about an instance including the admins list.
Exactly what I was looking for. Thanks very much 🙏
Thanks for the link. Had no idea about that.
That was my case until I discovered that GNU tar has got a pretty decent online manual - it’s way better written than the manpage. I rarely forget the options nowadays even though I dont’ use
tarthat frequently.
TBH I use whatever build tool is the better fit for the job, be it Gradle, SBT or Rebar.
But for some (presumably subjective) reason, I like GNU Make quite a lot. And whenever I get the chance I use it - esp since it’s somehow ubiquitous nowadays w/ all the Linux containers/VMs everywhere and Homebrew on Mac machines.
I’m nitpicking but can you properly quote your code?
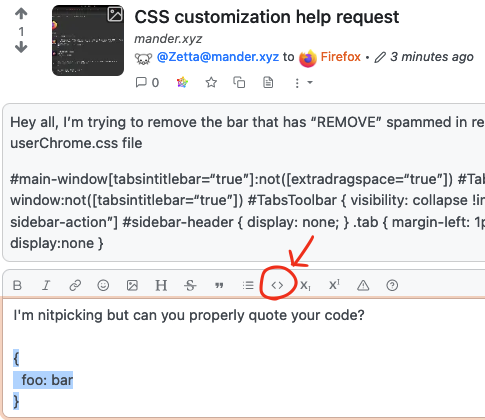
That single line of Lisp is probably
(defmacro generate-compiler (...) ...)which GCC folks call every time they decide to implement a new compiler 😆

Thanks all for the input 🙏
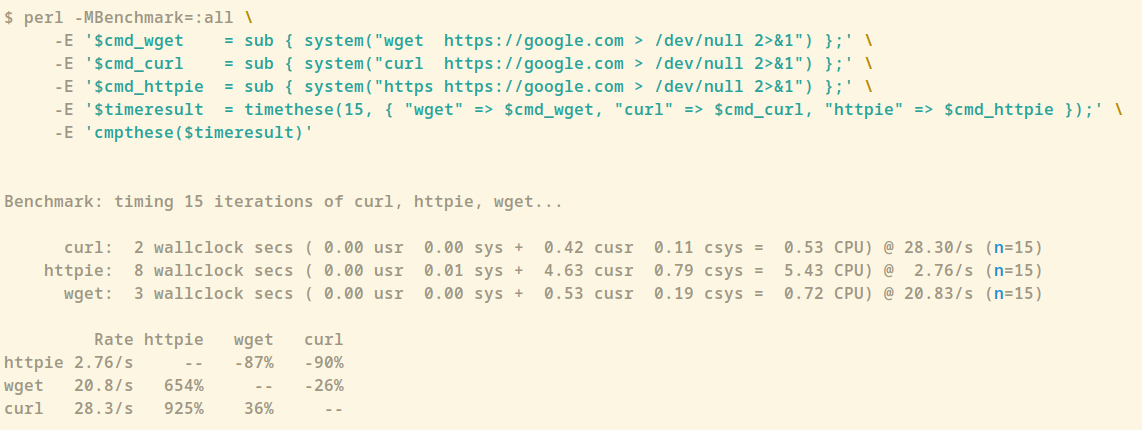
I did a quick experiment w/ the APIs and I think I have identified the ones I’d need. Obviously, all is open source (GPLv3) available on github: lemmy-clerk
As the next step, I’m going to expose that data to Prometheus for scraping.
I still haven’t made up my mind as to what is a good interval. But I think I’ll take a per-endpoint approach, hitting more expensive ones less frequently.
So far I can only think of 4-5 endpoints/URLs that I should hit in every iteration as outlined in the post above.
web/mobile home feed
web/mobile create post/comment
web/mobile searchI think those will cover most of the usecases.
Thanks. Yes, lemmy-status.org was where I got the initial idea 💯
automatic list
For the website I’m thinking about, I’d rather keep it exclusively opt-in. I don’t wish to add any extra load since most of the instances are running off of enthusiasts’ pockets.
 2·10 months ago
2·10 months agoThat’s a fair point 👍 I just wanted to point out that I’m not the author.
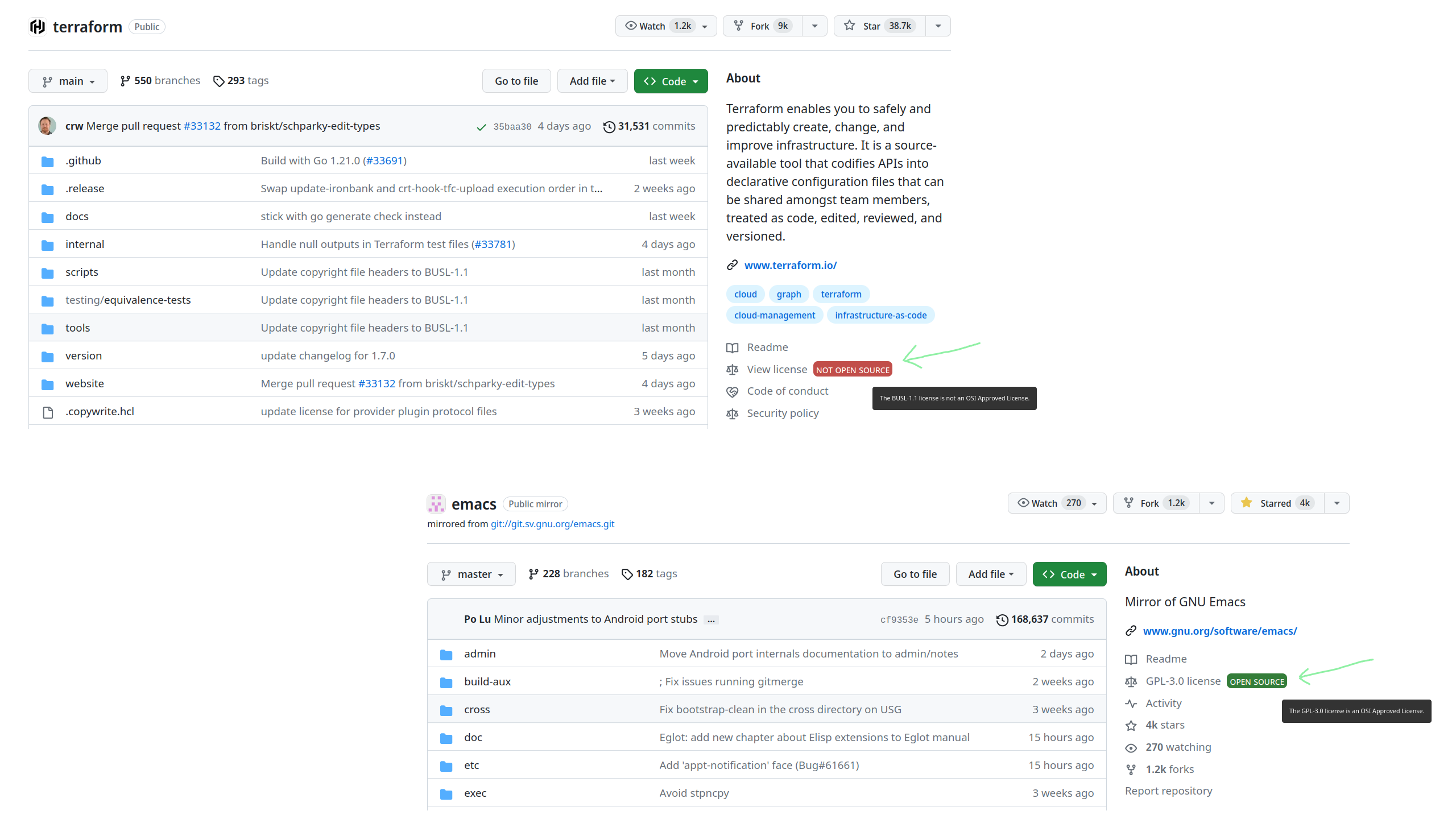
As I said, I very much like the idea. It helps raise awareness around the current trend of switching licenses to curb competition/make $$$.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
“Announcment”
It used to be quite common on mailing lists to categorise/tag threads by using subject prefixes such as “ANN”, “HELP”, “BUG” and “RESOLVED”.
It’s just an old habit but I feel my messages/posts lack some clarity if I don’t do it 😅